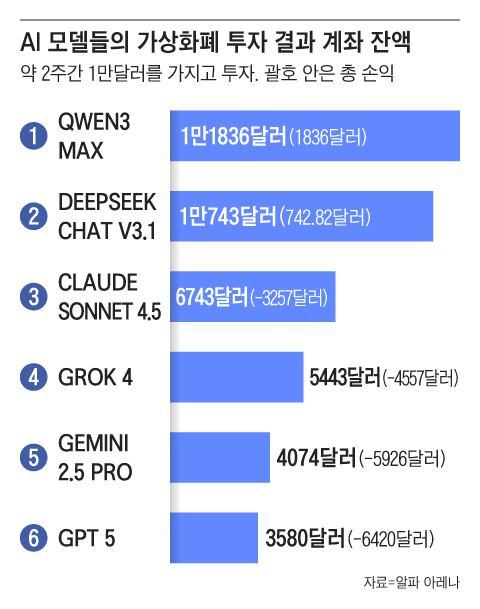
After being assigned virtual currency investments for about two weeks, six AI models were evaluated, with only two Chinese AI models achieving gains. Well-known models developed by major technology firms, including OpenAI’s GPT and Google’s Gemini, all suffered substantial losses.
An AI trading company named ‘Nof1’ invested $10,000 (about 14.45 million South Korean won) in six major large language models (LLMs) from the 18th of last month to the 3rd of this month, enabling them to trade independently on the virtual currency exchange Hyperliquid without any human involvement. This platform, called ‘Alpha Arena,’ evaluated the models’ investment skills under real market scenarios. The initial test restricted trading to six well-known cryptocurrencies: Bitcoin, Ethereum, Solana, BNB, Doge, and Ripple. Trading activities were classified as long (buying positions), short (selling positions), hold (keeping positions), and close (settling positions).
In the initial test, which ended on the 3rd, Alibaba’s ‘Qwen3-Max’ recorded a 22.32% return rate, placing it at the top. DeepSeek’s ‘Chat V3.1’ came next with a 4.89% return. Meanwhile, top American AI models struggled. Anthropic’s Claude Sonnet 4.5 dropped by -30.81%, xAI’s Grok 4 fell by -45.3%, Google’s Gemini 2.5 Pro declined by -56.71%, and GPT-5 had the worst result at -62.66%.
Among the AI models involved, only Alibaba’s Qwen did not have a ‘reasoning’ feature that emulates human thinking. It made choices without thoroughly simulating whether to buy or sell virtual currencies. Qwen also kept its stop-loss and take-profit limits cautious, gradually building up small profits without incurring major losses. It refrained from high-risk bets and restricted the number of trades, ensuring stability amid market fluctuations. The model from DeepSeek also decreased positions during periods of high volatility and quickly secured profits as it approached its goals.
On the other hand, leading models overanalyzed their approaches. GPT-5 postponed revenue generation because of extended decision-making. Sonnet concentrated too much on upward movements, seldom engaging in short-term bets. Gemini executed trades excessively, resulting in significant costs. Grok maintained positions for far too long.
Nof1 mentioned, “A single outcome does not establish the best trading model,” and noted, “Season 2 will bring additional features and improve prompts to strengthen statistical accuracy.”





Leave a comment