
As generative AI platforms such as ChatGPT and Perplexity become more widespread, an increasing number of users are stating, “Now, using AI for searching is more convenient.” However, the situation changes when precise information is essential. A clear example is this week’s College Scholastic Ability Test (CSAT). Naver, a top local portal, presents relevant content separately by using verified data from the Korea Institute for Curriculum and Evaluation and admissions companies. An industry expert noted, “AI does not inherently ensure accurate responses,” and mentioned, “Search engines have advantages in improving accuracy through authoritative sources and ‘data pipelines.’”
During testing of the ‘CSAT key schedule’ on Naver and ChatGPT, variations in accuracy were noted. ChatGPT indicated the application period as ‘August 26 to September 6,’ whereas the accurate period is ‘August 21 to September 5.’ The mistake happened because ChatGPT relied on unverified information available online. When questioned about the ‘2025 CSAT grade cutoffs,’ Naver’s answer was more precise.
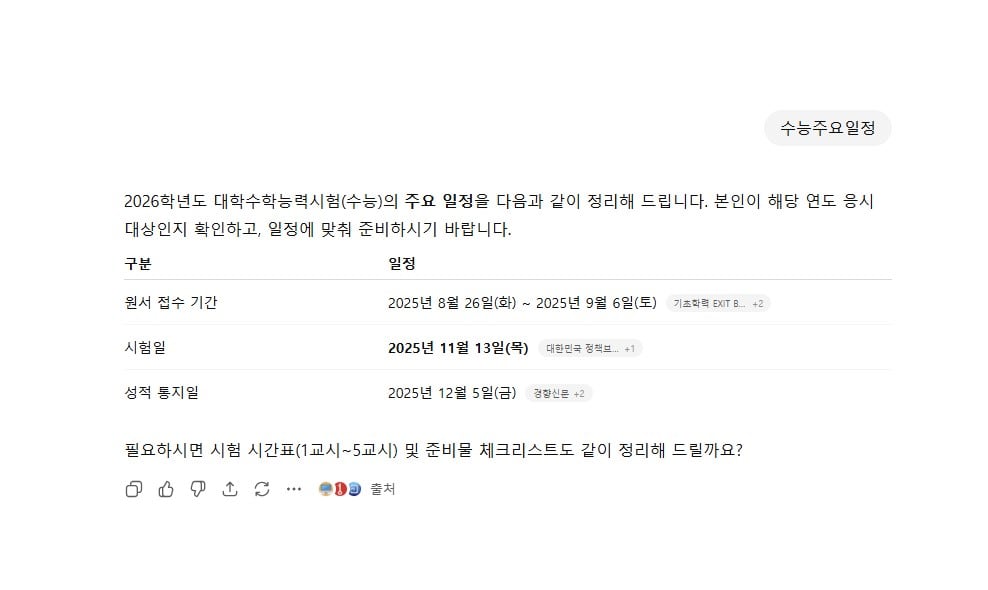
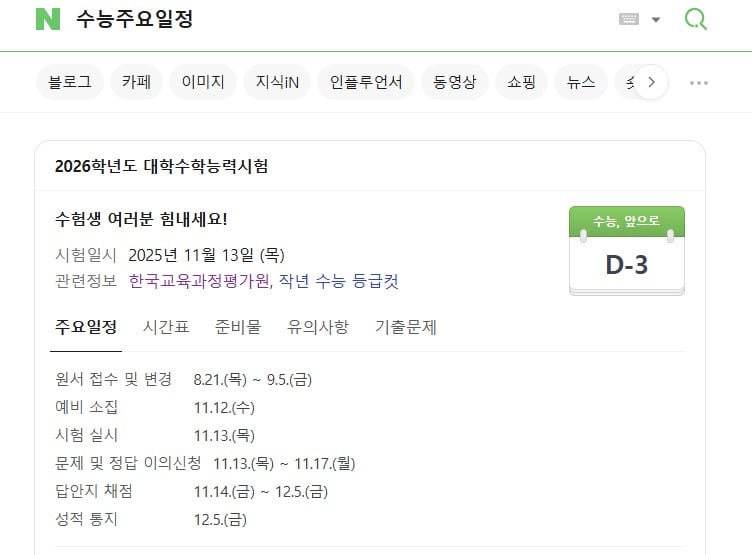
This distinction arises from Naver’s well-established ‘data pipeline.’ For significant domestic information such as the CSAT, Naver works with organizations like the Korea Institute for Curriculum and Evaluation, EBSi, and leading admission companies including Daesung MyMac and Jongno Academy. They perform manual verification of the data before making it available. Starting 30 days prior to the CSAT each year, they present distinct search results and continuously update essential schedules, timetables, study materials, and guidelines issued by the Korea Institute for Curriculum and Evaluation until the day before the exam. On the exam day, they promptly display the question papers and answer keys right after each subject ends, and once the exam is over, they include anticipated score thresholds and question patterns from major admission companies in the search results.
This framework is a component of Naver’s ‘answer-focused search’ approach. The same method is used for broadcasts, films, individuals, policies, and reference materials. Broadcast details are obtained directly from media outlets, movie data is sourced through collaboration with the film publication Cine21, and person-related searches involve self-submission along with institutional validation. Naver currently maintains data partnerships with numerous professional organizations, including 21 leading general hospitals, the Korean Legal Affairs Association, the Korean Architects Association, and the National Museum of Modern and Contemporary Art.
On the other hand, generative AI excels at condensing information from multiple sources and delivering it in a clear and comprehensible way. Nevertheless, as it relies on web-based documents, it cannot always ensure accurate responses. It might provide obsolete data or display links to information that no longer exists.
Because of this, Naver has implemented a ‘hybrid approach’ that tailors AI integration based on search intent instead of using it across the board. For exploratory searches such as ‘CSAT lunchbox menu’ or ‘CSAT encouragement phrases,’ they use AI summaries, but for queries that need accurate responses, they continue with direct data confirmation.





Leave a comment