DeepSeek’s V3.2-Special matches the reasoning abilities of Google’s Gemini 3 Pro, according to the Chinese startup.
Artificial intelligence start-up DeepSeekhas introduced its most advanced model version, DeepSeek-V3.2-Speciale, which is claimed to be comparable toGoogle DeepMind’s latest Gemini 3 Promodel in specific tasks, even though the Chinese company has restricted access to high-end semiconductor chips.
The breakthrough from the open-source laboratory has generated significant debate among AI researchers, occurring alongside the renowned annual Conference on Neural Information Processing Systems, known as NeurIPS.
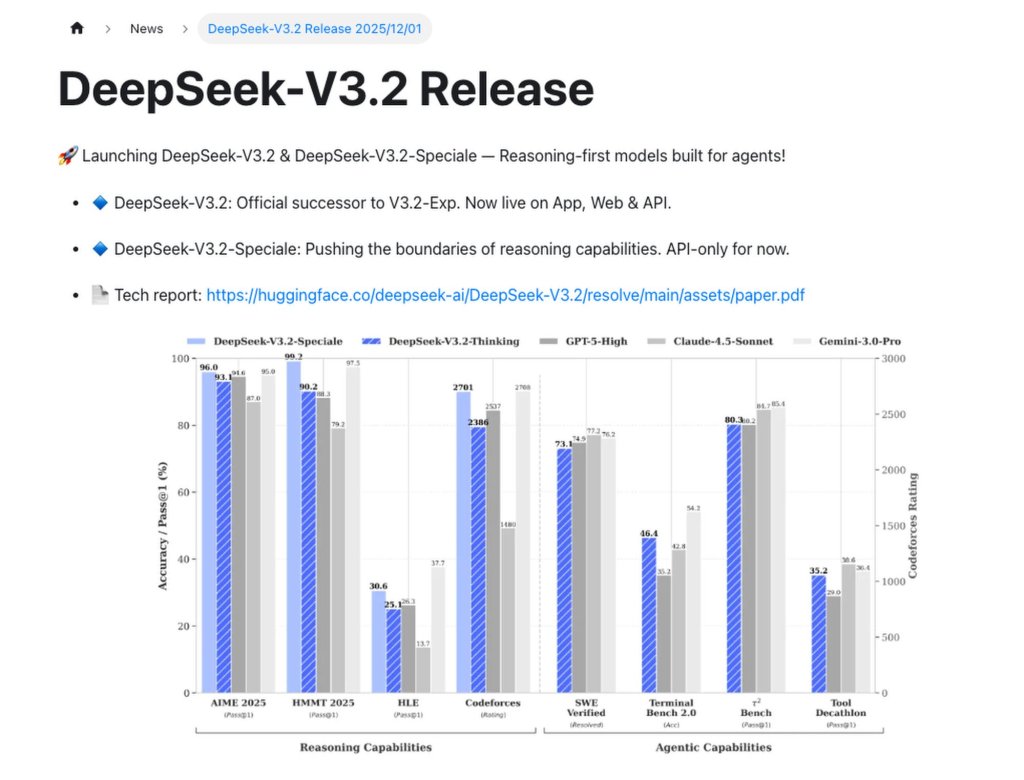
In its statement released on Monday, DeepSeek, based in Hangzhou, claimed that V3.2-Speciale matched Google’s Gemini 3 Pro, which came out two weeks prior, in terms of reasoning abilities, while the base version of V3.2, also unveiled on the same day, was comparable to OpenAI’s GPT-5 launched in August.
Are you curious about the most significant issues and developments happening globally? Find the solutions withSCMP Knowledge, our latest platform offering carefully selected content including explainers, FAQs, analyses, and infographics, presented by our acclaimed team.
DeepSeek mentioned that the V3.2-Special model attained top-tier results on the International Mathematical Olympiad test — a feat that was previously accomplished solely by internal models from OpenAI and Google DeepMind, which have remained undisclosed.
On social media, Susan Zhang, a principal research engineer at Google DeepMind, commended DeepSeek for the comprehensive technical documentation that comes with its latest models, highlighting the company’s work in improving model stability after training and boosting their ability to act autonomously.
Alphabet, the parent company of Google, saw its stock decline by 1.65 percent on Monday.
As stated in its technical report, DeepSeek achieved this even though it had “fewer overall training FLOPs” compared to its American competitors, primarily because of export restrictions that hinder Chinese access to cutting-edge semiconductor chips. FLOPs, which stand for floating point operations per second, are the conventional metric used to assess computing power in AI model training.
DeepSeek has released its V3.2 on the Hugging Face developer platform, whereas V3.2-Speciale can only be accessed via an application programming interface (API), as stated in the announcement, because of its increased token consumption.
The cost for this model version is $0.28 per million input tokens and $0.42 per million output tokens. In contrast, Gemini 3 Pro charges API users as much as $4 per million input tokens and $18.00 per million output tokens.
Nevertheless, DeepSeek admitted that its model was “considerably less efficient” than Gemini 3 Pro in terms of token usage, suggesting that V3.2 needed more tokens to handle the same request. The company explained this limitation as a result of its lack of processing power, which also impacted the model’s “global understanding” when compared to Gemini 3 Pro.
DeepSeek mentioned it planned to bridge these gaps by increasing the computational resources utilized in training models, a technique alsoused by Google DeepMind. DeepSeek researcher Gou Zhibin mentioned on social media that the so-called scaling method was not encountering any so-called “barrier”.
The latest model from DeepSeek “provides a very clear response” indicating that “compute continues to be the key factor determining who is leading the AI competition,” stated Patrick Zhang, ByteDance’s global head of technology policy and law, in his Geopolitechs newsletter.
In a world where most cutting-edge models have comparable access to information, those that train more extensively, expand further, and operate for longer periods ultimately shape the course of the industry.
The unveiling of DeepSeek’s model before NeurIPS has been likened to OpenAI’s launch of ChatGPT in late November 2022, which also occurred during that year’s conference in New Orleans.
Generally low-key, DeepSeek has not revealed if it will send employees to this year’s conference. Any DeepSeek researcher in attendance was expected to draw considerable attention, noted Florian Brand, an authority on China’s open-source AI environment who is participating in this year’s NeurIPS in San Diego.
“All the group chats today were bustling following DeepSeek’s announcement,” he said.
This year, the conference is being held at the same time in two places – San Diego and Mexico City – because of worries about obtaining US visas for international researchers. Several Chinese attendees have chosen to participate in the Mexico City session.
More Articles from SCMP
Senior Chinese official criticizes US approach to deep-sea mining activities
This piece was first published in the South China Morning Post (www.scmp.com), a top news outlet covering China and Asia.
Copyright (c) 2025. South China Morning Post Publishers Ltd. All rights reserved.





Leave a comment